Magellan.Surveyor Documentation
David Heise
Indiana University
[email protected]
Indiana University
[email protected]
Magellan is an ongoing research project in which dictionaries of affective meaning are being collected around the world. Surveyor is a Java applet that measures affective meaning in indigenous languages, and that archives data in the U.S.A. via the Internet, or else archives data on field computers used to interview respondents.
The Surveyor Program |
Magellan Projects |
Translating Interface Texts |
Creating Stimuli Files |
Unicode |
Applet Web Page |
Data Format |
Saving Data Locally |
The Surveyor Program
Surveyor is a Java applet that runs in World Wide Web (WWW) browsers and collects data from respondents. Surveyor has the following features.
| Being a Java applet that runs in a WWW browser, Surveyor can be made available to respondents anywhere in the world. | |
| The program is fully internationalized. It can be set up for indigenes reading any of the world's written languages. This document explains how to set up the program in a language that has not been used before. | |
| Design of a study is controlled by the researcher who creates the set of files described in this document. | |
| A respondent begins a session with multiple-choice questions and continues with ratings of stimuli on graphic rating scales. | |
| Any number of multiple-choice questions may be included. Each question may have as many as ten options. | |
| Any number of stimuli may be included. A stimulus may be any text that appears on a single line or on two lines - words, phrases, sentences. | |
| Three different ratings are obtained for each stimulus, corresponding to the universal dimensions of affective meaning: Evaluation, Potency, and Activity (EPA). | |
| Questions and stimuli may be divided into subsets that are presented to different respondents. Thereby data can be collected on more items than any one respondent could manage. | |
Randomization is used at
critical points:
In other words, a respondent will be assigned a randomly-chosen subset of items; the order in which stimuli from that subset are presented will be randomized; the order of presenting EPA scales for each stimulus will be randomized; and every presentation of a rating scale will have its positive end randomly assigned to the left or the right. | |
| The respondent interacts with Surveyor entirely via the computer mouse - clicking question options, clicking buttons, and dragging a slider along a graphic scale. The keyboard is not used in answering questions or in making ratings. | |
| The graphic rating scales can work in high-speed mode, where a rating is completed as soon as the respondent finishes dragging the slider along the scale. Alternatively, the procedure can involve two steps: move the slider to a desired position, then click a save-button. The researcher chooses which approach is used. | |
| Respondents are allowed to skip a stimulus that is unfamiliar to them. The skipping procedure requires clicking a button, and confirming intent in a pop-up dialog. | |
| Respondents are allowed to re-rate any stimulus. The procedure is to click a button and make a selection from a list of all completed stimuli. Data on the selected stimulus are erased, and the selected stimulus becomes the next stimulus to be rated on all three EPA scales. The opportunity to re-rate stimuli is offered automatically at the end of a session. | |
| Surveyor includes a tutorial and practice regarding the use of graphic scales, skipping stimuli, and re-rating stimuli. The researcher determines whether or not the tutorial is part of respondents' sessions. | |
| Surveyor can collect a respondents' names and addresses in order to compensate them for their work. The program is designed so that the personal information is emailed to a researcher and then discarded. The personal information cannot be linked to a respondent's answers. The researcher determines whether or not the identifying questionnaire is included in a session. | |
| Surveyor assigns each respondent a unique series identification number, and the respondents are told to write down their numbers so that they can prove that they completed the task. The number is provided whether or not personal information is gathered, and it is available to the respondent even if an Internet transmission fails. | |
| The respondent is sent to a new WWW page on completing a session. The content of this page is provided by the researcher. | |
| Respondents' data is assembled electronically via the Internet into data sets at Indiana University. The researcher can download the data at any time. Alternatively, data is assembled in a directory on the interviewing computer provided to respondents. |
Java source for the Surveyor2 applet is available online.
Magellan Projects
Using Surveyor to obtain a dictionary of affective meanings in a culture requires the following steps.
Translation and study design:
| |
Establish the project on the
Internet by getting David Heise to create a directory within www.indiana.edu/~socpsy/surveyor2/
that contains
Alternatively, these materials can be stored in a directory on each interviewers' computer for use in the field, without connection to the Internet. | |
| Get a sample of indigenes to visit the Surveyor web page and rate the concepts presented to them by Surveyor. | |
| Obtain the archived data from the project directory within www.indiana.edu/~socpsy/surveyor2/, and use standard software like SPSS to generate summary statistics. Data acquired in the field apart from an Internet connection is available in the project directory on the interviewer's computer. | |
| Prepare dictionaries in formats that allow the data to be analyzed in Java Interact, have those dictionaries compiled as Java resources, and include the Java files in the JavaInteract directory at www.indiana.edu/~socpsy/. |
Once dictionaries are available, a second phase of culture exploration can be undertaken: estimating impression-formation equations. Surveyor can be used for data collection in this work, too.
Currently, the Internet part of a project must be implemented through David Heise at Indiana University who maintains the World Wide Web location supporting Magellan research: www.indiana.edu/~socpsy/surveyor2/. You provide
| a "Messages.java" file if you are working in a language that has not been used previously in a Magellan project; | |
| stimuli files named "Words_1.java", "Words_2.java", etc.; | |
| an HTML file for the applet, which defines the Surveyor options you wish to invoke; |
as described below. Then Dr. Heise will
| compile the Messages and Words Java files into the Surveyor program; | |
| create a special directory for your project within www.indiana.edu/~socpsy/surveyor2/; | |
| upload the compiled Messages and Words files (the Java class files) for your project to a subdirectory named "surveyor2" within your special directory; | |
| upload the Java archive file "surveyor2.jar" to your special directory; | |
| upload the applet web page to your directory; | |
| upload a template file, "archiver.tpl", defining how your data should be archived when they arrive over the Internet; | |
| tell you the URL of the web page that runs Surveyor for your project, and the URL of the index allowing you to retrieve your data. For example, the URL of the fast version of Surveyor linked above is http://www.indiana.edu/~socpsy/surveyor2/Example/SurveyorLite.html and the index is at http://www.indiana.edu/~socpsy/surveyor2/Example/. |
A flowchart offers some perspective on these processes. It appears in a separate window so you can compare it to the texts above.
This document provides details on topics that you must understand in order to submit required materials to Dr. Heise.
Translating the Surveyor Interface Texts
This section is relevant only if you need to make Surveyor operate in a language that Surveyor has not used previously. The file described here need not be provided if you will operate in one of the available Surveyor languages: English, simplified Chinese, Japanese, German, Arabic.
Translating Surveyor into a new language has two aspects: dealing with the texts that define Surveyor's bipolar rating scales, and providing indigenous texts for the rest of Surveyor's user interface.
The texts for scales and user interface are defined in a Java file named Messages.java. You copy that file and put translations into it for compilation into the Surveyor program.
Scales
Surveyor measures affective meaning on the dimensions of Evaluation, Potency, and Activity. Here is an English version of Surveyor's Evaluation scale:
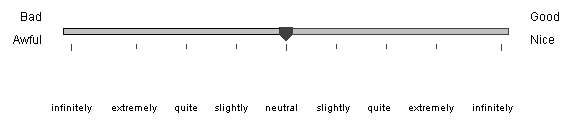
A translation has to convert all of the words defining the scale into the indigenous language. For example, here is the Japanese version.
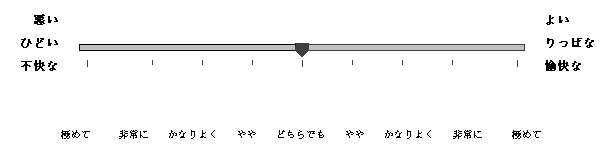
The anchors defining the ends of scales in non-English languages are not mere translations of the adjectives defining the scales in English. Rather, the non-English adjectives come from prior research indicating how each dimension of affective meaning is best defined indigenously. This is discussed in detail in a book by David Heise, Surveying Cultures (Wiley-Interscience, 2010). Research has been done in 31 different societies/languages, and scale definitions in these languages should make use of the prior research. Translation of scale anchors into societies/languages other than the 31 already studied listed should be informed by studying prior research on related languages. For example, German scales were defined by considering the scale definitions in Dutch and English. Languages that are very different than those already studied may require new scale-development research.
The English adverbs slightly, quite, extremely define approximately equal intervals along the rating scale, and infinitely defines somewhat longer intervals at the ends of a scale (D. Heise. 1969. "Some methodological issues in semantic differential research." Psychological Bulletin, 72:. 406-22. D. Heise, 1978, Computer-Assisted Analysis of Social Action, Chapel Hill, N.C.: Institute for Research in Social Science). Lacking research on magnitude effects of adverbs in other languages, these English adverbs should be translated as precisely as possible.
The following table shows definitions for scales in English on the left, and definitions for scales in German on the right.
|
English Scale Texts |
German Scale Texts |
|
{ "Pos_1_1", " " }, |
{ "Pos_1_1", "angenehm" }, |
The table illustrates rules for translating scale texts in Messages.java.
| Each line of Messages.java consists of a pair of quoted texts. The first (e.g., "Pos_1_1") is a key and must not be modified in any way. Punctuation outside of quotes also must not be changed (i.e., brackets and comma). Texts in the indigenous language can be placed only within the second set of quotes on a line. | |||||||
| Five adjectives define each end of a scale, but rarely will so many adjectives be used. Blank the adjective positions that are not in use with a space between the quotes for the indigenous text. | |||||||
Surveyor's numerical
coding of ratings depend on the following relations.
|
Translations often will require specifying special characters with unicodes, as detailed below.
User Interface
Surveyor has a variety of prompts and messages, and Surveyor provides a tutorial on how to use its computerized scales. The texts of the prompts, messages, and instructions must be translated to the indigenous language in order to be intelligible to indigenes.
For example, Surveyor uses a Cancel button in one of its dialogs, and the English text for this button is defined as follows in Messages_en_US.java.
{ "cancelSkipButton", "Cancel" },
The German language version of Surveyor has to give a German name to the button in Messages_de_DE.java, as follows.
{ "cancelSkipButton", "Abbrechen" },
The complete set of texts that require translation are given in the following table. Notes for translators follow the table.
|
|
{ "questionnaireInstruction", "Click the mouse pointer on your answer, then click the \"Okay\" button." }, |
| The quoted keywords at the left of each line must not be changed. | |
| Each line in the table specifies a single line of text. The translated text must display as a single line. | |
| The characters \" are used to specify a quote within the interface text. Quotes without a backslash are punctuation in the Java program. | |
| The text defined by questionnaireInstruction appears above each background question. | |
| The next nine lines - keyed questionnaireContinueButton through submit - are labels for buttons that appear at various places in the program. | |
| labelForNumberUndone defines a message that tells the respondent how many stimuli are yet to be rated. The number of undone stimuli will be concatenated to the end of this text, and the message will appear below the rating scale between the correct button and the skip button. (The point at which this message begins appearing is controlled by an applet parameter, BeginCountdownAt.) | |
| The lines keyed concludingQuery1 through concludingQuery3 appear together and define the message shown above a box listing all stimuli after the respondent has rated all stimuli. A translation may distribute information as desired over the three lines, as long as the same basic message is conveyed. | |
| The lines keyed formInstruction1 through city relate to the form for acquiring the respondent's name and address so that compensation can be provided. | |
| The lines keyed thankYou1 through thankYou3 comprise the message shown with nothing else on the screen at the very end of a session, while data are being transmitted to Indiana University. This display gives way to the successful-session web page (or conceivably to an error message). | |
| The line keyed pinText is the instruction regarding the respondent's unique identification number. | |
| The line keyed stopCardText is an error message presented when data could not be saved over the Internet. Hopefully, this will never happen. | |
| TutorialStimulus1, TutorialStimulus2, and TutorialStimulus3 are stimuli used in the tutorial. Each is shown separately. The first should be a pleasant and lively concept, the second should be a neutral concept, and the third should be a concept few people recognize. | |
| The remaining lines, with keys like Tutorial_1_1, define the texts used in the tutorial. The first number in the key refers to the page of the tutorial, the second number refers to the line of text on that page. The three lines of text on a page are presented together, and may be rewritten as desired, as long as the message is conveyed. |
Surveyor reads definitions of scales and messages from a single file called Messages.java. If you are translating Surveyor to a new language, then download Messages.java, and modify that file. Messages.java is a text-only file and should be saved with the same name, specifying it as being simple text. Afterwards you may have to change the extension from "txt" back to "java". (Heise will elaborate the file name with proper insertions when he compiles the Java file; e.g., the German version of Messages.java becomes "Messages_de_DE.java".)
Creating Stimuli Files
Different projects ask respondents to answer different background questions and to rate different stimuli. Whatever the content, however, questions and stimuli must be incorporated into Surveyor using a standard format, shown in the following table.
|
|
|
package magellan; |
In general:
| The first two lines are required Java code, and should not be changed. | |
| The third line is required Java code, and should not be changed except for matching the number to the stimuli set. For example, if you have 25 stimuli sets, then the last set would be defined in a file with this third line: public class Words_25 extends ListResourceBundle {. The name of the file would be Words_25.java. | |
| The fourth line is required Java code, and should not be changed. | |
| "Example" in the fifth line line, keyed projectIdentification, should be changed to name your directory at Indiana University. The name should be a single word of 32 characters or less that includes the place, season, and year of data collection: e.g., GreatLakesNavalBaseFall62 or TexasTechSpr01. | |
| "_1" in the sixth line line, keyed stimuliSetIdentification, should be changed to an underline character and the number identifying the stimulus set - the same number as was entered in the third line. | |
| The line containing { "textArray", new String[] { is required Java code, and should not be changed. |
The line containing "|Are you:|Female|Male|", "|Are you:|Female|Male|", illustrates how to format a background question. The duplication is not an error. The first entry in quotes is the text of the question in the indigenous language, for presentation to respondents. The second quoted entry on the line is the text of the question in English, for use in archiving the data. In this example, the indigenous language is English, so the two entries are identical, but in general the two entries will be in different languages.
Here are considerations to keep in mind when incorporating questions into Surveyor files.
| Concatenate the question stub and all options into a single string of text, and enclose that string in quotes followed by a comma. | |
| The first entry on a line must be the question's text in the indigenous language. The second entry on a line must be the same question in English. (The two entries go on the same line for the sake of clarity. However, in the case of a long question, the indigenous language version may be placed on one line, and the English translation on the next line. Also the English language stub may be abbreviated since it is never displayed.) | |
| Do not use commas within the English translation. The English translation of a respondent's answer is included in the respondent's data record, and included commas would be interpreted as field delimiters. | |
| The string for a question must begin with a vertical bar, which is the signal to Surveyor that the quoted text is a background question rather than a stimulus. A second vertical bar signals the end of the question stub, and the beginning of the first option. Subsequent vertical bars signal ends and beginnings of options. A vertical bar is required at the end. Formatting with vertical bars is done for both the indigenous language version and the English version. | |
| Ten or fewer options may be included in a question. | |
| The question stub is displayed on the form as a centered line. Each option is displayed below the stub on a separate line that begins with a radio button, initially unselected. | |
| The respondent moves to the next form by clicking on an option and then clicking the questionnaireContinueButton. The respondent cannot go to the next form until an option has been selected on the current form. | |
| There is no formal limit on the number of questions to be asked. |
Stimuli for EPA rating follow the questions. The example in the table has six stimuli. Some considerations regarding stimuli follow.
Each stimulus requires two
entries on a line, each entry enclosed in quotes and followed by a
comma.
| |
| Do not use commas within the English keyword. The English keyword is included in the respondent's data record, and included commas would be interpreted as field delimiters. | |
| A multiword stimulus can be spread over two lines when displayed by Surveyor by including a vertical bar between the end of the first line and the beginning of the second line. | |
| Stimuli for impression formation projects should employ multiple sentences on two lines, as in the next to last example above. (A subtext cannot be emphasized within the stimulus using italics, bold, or underlining.) | |
| While there is no formal limit on the number of stimuli, 100 generally is considered the maximum a respondent can attend to in a single sitting. The problem is being able to concentrate on a tedious task rather than amount of time consumed, since most respondents finish rating 100 stimuli in less than half and hour (see graph below). Partition a larger set of stimuli into subsets defined in different stimuli files. Surveyor will assign stimuli sets randomly to different respondents. |
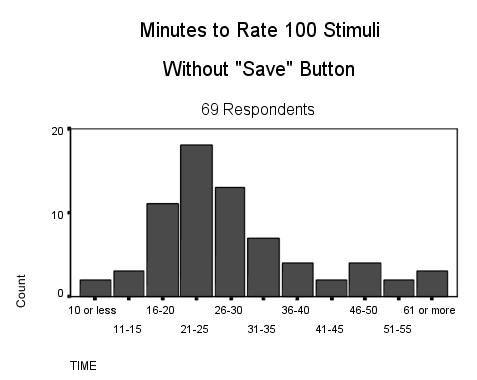 |
With 100 stimuli, each
additional 5 minutes of rating time means a respondent spent one
additional second per scale on the average. E.g., 10 minutes of rating
time implies that the respondent spent an average of two seconds for
each scale rating.
Respondents who spend less than three seconds per rating (i.e., less than 16 minutes in rating 100 stimuli) produce obviously shoddy data. You can check the number of minutes each respondent spent on the ratings: it is the third item in a respondent's data record. Employing the "Save" button adds five to ten minutes to the time required for rating 100 stimuli. |
Stimuli files are named Word_1.java, Word_2.java, etc. The number of the file should match the number of the class in line three of the file. Stimuli files are text-only files, and should be saved as simple text files, even though they must end up with a "java" extension.
One method of building randomly selected subsets of stimuli. Suppose you have 1,500 stimuli in column B of an Excel worksheet, and you want to divide this list into 15 randomly selected subsets. Enter this formula in the cells of column A: =CEILING(15*RAND(),1). Random numbers between 1 and 15 appear in column A defining the subset for each stimulus. Copy the two columns to a new worksheet, paste as values, and sort on column A. The stimuli now are organized into 15 sets. The randomly-drawn sets have varying number of stimuli, so you have to randomly shift some stimuli from overly-large sets into overly-small sets in order to even out all sets to 100 stimuli each.
Another method of building randomly selected subsets of stimuli. Suppose you have 1,500 stimuli in the SPSS data editor, the actual stimuli in a string variable named "stimulus" and the English translation in a string variable named "key". Chose Data / Select Cases / Random Sample / Exactly 100 from the first 1500 to get the first sample of one hundred. Transform the "filter_$" variable produced by SPSS to a new variable called "sample", and sort on that variable. Then select another random sample of 100 from the first 1400 cases, and continue the procedures repeatedly until all 15 random samples of 100 stimuli are defined.
Unicode
This section is relevant only if you need to make Surveyor operate in a language that Surveyor has not used previously, and that language does not use Latin characters.
Most non-European languages use non-Latin characters in their printed renditions. Texts in these languages must be expressed in Unicode (\udddd notation) in order to be usable in Surveyor. Unicode is an internationally supported system providing a standardized number for each character in every written language. Charts for converting characters to unicodes are provided by the Unicode Consortium.
For example, here is how the Japanese evaluation scale shown previously gets defined in Surveyor (\u signals that the next four characters are a unicode in the form of a hexadecimal number).
{ "Pos_1_1",
"\u3088\u3044" },
{ "Pos_1_2", "\u308a\u3063\u3071\u306a" },
{ "Pos_1_3", "\u6109\u5feb\u306a" },
{ "Pos_1_4", " " },
{ "Pos_1_5", " " },
{ "Neg_1_1",
"\u60aa\u3044" },
{ "Neg_1_2", "\u3072\u3069\u3044" },
{ "Neg_1_3", "\u4e0d\u5feb\u306a" },
{ "Neg_1_4", " " },
{ "Neg_1_5", " " },
Punctuation characters !()-[]:;',.? may be entered between unicodes in their Latin form. Quotation marks within text have to be preceded with a backslash \" to distinguish them from quotes used in the Java program.
A program for Windows called native2ascii.exe (Native-to-ASCII) transforms native-language texts into unicode. First, a file is created with text in the native language, created on a computer that routinely operates in the native language. Then native2ascii.exe is used to create a new file in which native-language characters are converted to unicode. (The native2ascii.exe program leaves Latin characters in their native form.)
For example, suppose you wrote just this one line on a Japanese computer with Shift-JIS encoding
![]()
and saved it in a
file called source.txt in the same directory as the native2ascii.exe
program. Then you run the conversion program with the following command
from the
MS-DOS prompt:
native2ascii -encoding SJIS source.txt
output.txt
and you get a new file in the same directory called output.txt
which
contains the one line:
{ "Pos_1_1", "\u3088\u3044" },
This is the first line of Surveyor's definition of the Japanese evaluation scale. Similarly, translations throughout Surveyor's Messages.java file could be defined in native Japanese, and then the whole file could be converted to unicode with native2ascii.exe. The same procedure can be used with stimuli files.
The native2ascii.exe program is included in the bin directory of the standard edition of the Java platform, which can be downloaded without charge from Sun Microsystems. Documentation for Native-to-ASCII also is available from Sun on the web.
The European set of numeric digits is not used in all languages. You assure that digits will be shaped properly for indigenes in your study by giving the unicode character for the indigenous zero digit in a line at the top of the Messages.java file.
{ "UnicodeZero", "\u0030"},
The unicode value shown above is for European digits. To provide
digits shaped for Arabic, for instance, you would replace \u0030 with
\u0660.
Applet Web Page
The Surveyor applet is presented on a web page that has to be set up by the researcher and provided to Heise as a file for uploading. The file should be saved as a text file, with a name like surveyor.txt, even though the extension then will have to be changed from "txt" to "htm". Do not save as an HTML file from a word processor, because word processors like Word bloat HTML files with unnecessary code that makes Heise's job harder.
The text in the file should be identical to the text shown in the box below except for the values of the parameters.
|
|
<HTML> |
The researcher has to set the values of the parameters.
| PARAM NAME=NumberOfStimuliSets. The VALUE of this parameter must equal the number of different stimuli sets in the project. | |
PARAM NAME=ForceStimuliSet.
Except when testing stimuli sets, the VALUE of this parameter must
equal 0. If the VALUE equals a number greater than zero, then that
stimulus set will be used by Surveyor, rather than selecting a
stimulus set randomly. The VALUE of ForceStimuliSet must not be greater
than the VALUE of NumberOfStimuliSets.
| |
| PARAM NAME=BeginCountdownAt. This parameter defines the point at which the respondent starts getting information on how many stimuli are left to rate. For example, if there are 90 stimuli in the set and the message should begin appearing halfway through, then set VALUE=45. Setting the value greater than the number of stimuli causes no message to appear at any time. | |
PARAM NAME=UseSaveButton.
This parameter allows the rating scale to work in two different ways.
| |
| PARAM NAME=GiveTutorial. If VALUE=true, the Surveyor tutorial is presented after the background questions have been completed and before any stimuli are presented for rating. No tutorial is presented if VALUE=false. | |
| PARAM NAME=Language and PARAM NAME=Country: the values of these parameters set the language for Surveyor, assuming the corresponding Messages file has been uploaded. For example, PARAM NAME=Language VALUE="es", and PARAM NAME=Country VALUE="MX" presents Surveyor in Spanish (Mexico) if Messages_es_MX.class, compiled from Messages_es_MX.java, has been uploaded. | |
| PARAM NAME=Typesize VALUE="10" may have to be set to a smaller size with expansive languages. For example, Spanish words used on the rating scale are so long that the minimum typesize has to be set to 9 points instead of 10 points. Some languages like Arabic require a larger size. | |
| PARAM NAME=MeasuresPerStimulus. VALUE="3" by default, representing the three-dimensional EPA measurements of typical Magellan studies. The value may be set as high as 25 to implement a classic semantic differential study with many scales. However, the additional scales must be defined in the Messages file; e.g., if there were 4 measures per stimulus then the Messages file would have to define Pos_4_1, Pos_4_2, Pos_4_3, Pos_4_4, Pos_4_5, and also Neg_4_1, Neg_4_2, Neg_4_3, Neg_4_4, Neg_4_5. | |
| PARAM NAME=LineOfAdverbs also helps manage expansive languages. If the value is true all adverbs are on a single line. If false, the adverbs are staggered on two lines, allowing the words to overlap. | |
| PARAM NAME=AcquiringPersonalData determines whether respondents' names and addresses will be acquired. If VALUE=true, a form for obtaining the respondent's name and address is presented at the end of all ratings, and this information is emailed to the address specified in the Email parameter. If VALUE=false, the form is not displayed. | |
| PARAM NAME=Anonymous. If VALUE=true, then names and addresses are discarded after the email, and they cannot be connected to a respondent's data. If VALUE=false, then the personal information is stored in the respondent's data file. Retaining personal information may be necessary in longitudinal studies, but should be avoided otherwise. | |
| PARAM NAME=Email provides the email address of the person responsible for administering remuneration. If Value="" then the email will be sent to [email protected], and emails sent there will be trashed periodically, without warning. | |
| PARAM NAME=successURL provides the address for a World Wide Web page where respondents are sent after completing the ratings. The researcher can design the page as desired. If Value="" then respondents are left on the Surveyor web page, and they are shown a final form that presents a thank-you, tells them their data has been saved, and that presents each respondent with a unique identification number (the number of microseconds since August 3, 2001) that they may write down to prove that they completed the task. Respondents' unique identification numbers are not stored with their data when data are saved via the Internet. | |
| PARAM NAME=DebuggingSkip causes the Skip button to move immediately to the next stimulus, if the value is true. This parameter is used only when proof-reading stimuli. | |
| PARAM NAME=InternetSave should have the value of true if data are to be transmitted over the Internet and stored at Indiana University. The value would be false if data are to be stored locally, as discussed below in the section titled Saving Data Locally. |
Data Format
Data obtained with stimulus set Words_X.java are appended to an archive file named Data_X.dat. The archive file is created if it does not yet exist. For example, suppose that a first respondent answers the questions and does the ratings of stimuli in your Words_3.java stimuli file. When this respondent's data are stored, a file named Data_3.dat is created in your project directory, and the first respondent's data is saved in it. Later when a second respondent answers the questions and does the ratings of stimuli in Words_3.java, the second respondent's data are appended at the end of Data_3.dat.
In an Internet project, you can examine the data files at any time with a WWW browser by visiting the URL:
where YourDirectory is the name of your project directory at Indiana University. An index is displayed showing all of the files in your directory, and you may click on the name of a data file to examine its contents.
You can download a data file by right-clicking on the name in the index and selecting "Save link as". (This is a Windows procedure; comparable procedures are available in browsers running on other platforms.)
Data from a respondent constitute one record. Respondent records are separated by two blank lines.
Each record in a data file is structured as follows:
First line:
| |
Background question lines
are next.
| |
Ratings of stimuli are the
final lines in a respondent's record, in the same order as stimuli were
listed in the stimuli file.
|
The total number of variables is: 5 on the first line, plus 2 times the number of background questions, plus four times the number of stimuli. For example, with three background questions and 100 stimuli, there will be 410 variables in the dataset.
A data file can be imported directly into SPSS by specifying the number of variables per record (500 maximum) and indicating that fields are comma-delimited. SPSS will treat end-of-line as a field delimiter, without user specification. (This works only if stimuli do not contain embedded commas.)
Data also can be imported into SPSS using a syntax file, and this approach allows more than 500 variables per record. For example, the following syntax file reads a data file that contains answers to questions about sex, race, geographic origin, and marital status. The syntax file then gets stimulus text and respondent EPA ratings for 100 stimuli. Then the syntax file sets missing-data values for the EPA ratings. Stimuli texts are read using A format, and the specified length of the stimulus field (e.g., A35) must be greater than the number of characters in any stimulus.
DATA LIST FILE = 'D:\Magellan\IU0102\DATA\26_03_02data.dat' FREE /
TIMESTAMPWORD (A10)
ID (F14.0)
STIM_SET_NAME (A10)
STIM_SET (A10)
SKIPPED_NAME (A10)
SKIPPED (F3.0)
EDITED_NAME (A10)
EDITED (F4.0)
MINUTES_NAME (A10)
MINUTES (F4.0)
SEX_WORD (A6)
SEX (F1.0)
RACE_WRD (A35)
RACE (F1.0)
REGION_W (A55)
REGION (F1.0)
MARITAL_ (A15)
MARITAL (F1.0)
VAR001 TO VAR400 (100((A35) (3F6.2))).
MISSING VALUES VAR002 TO VAR004 VAR006 TO VAR008 VAR010 TO VAR012
VAR014 TO VAR016 VAR018 TO VAR020 VAR022 TO VAR024 VAR026 TO VAR028
VAR030 TO VAR032 VAR034 TO VAR036 VAR038 TO VAR040 VAR042 TO VAR044
VAR046 TO VAR048 VAR050 TO VAR052 VAR054 TO VAR056 VAR058 TO VAR060
VAR062 TO VAR064 VAR066 TO VAR068 VAR070 TO VAR072 VAR074 TO VAR076
VAR078 TO VAR080 VAR082 TO VAR084 VAR086 TO VAR088 VAR090 TO VAR092
VAR094 TO VAR096 VAR098 TO VAR100 VAR102 TO VAR104 VAR106 TO VAR108
VAR110 TO VAR112 VAR114 TO VAR116 VAR118 TO VAR120 VAR122 TO VAR124
VAR126 TO VAR128 VAR130 TO VAR132 VAR134 TO VAR136 VAR138 TO VAR140
VAR142 TO VAR144 VAR146 TO VAR148 VAR150 TO VAR152 VAR154 TO VAR156
VAR158 TO VAR160 VAR162 TO VAR164 VAR166 TO VAR168 VAR170 TO VAR172
VAR174 TO VAR176 VAR178 TO VAR180 VAR182 TO VAR184 VAR186 TO VAR188
VAR190 TO VAR192 VAR194 TO VAR196 VAR198 TO VAR200 VAR202 TO VAR204
VAR206 TO VAR208 VAR210 TO VAR212 VAR214 TO VAR216 VAR218 TO VAR220
VAR222 TO VAR224 VAR226 TO VAR228 VAR230 TO VAR232 VAR234 TO VAR236
VAR238 TO VAR240 VAR242 TO VAR244 VAR246 TO VAR248 VAR250 TO VAR252
VAR254 TO VAR256 VAR258 TO VAR260 VAR262 TO VAR264 VAR266 TO VAR268
VAR270 TO VAR272 VAR274 TO VAR276 VAR278 TO VAR280 VAR282 TO VAR284
VAR286 TO VAR288 VAR290 TO VAR292 VAR294 TO VAR296 VAR298 TO VAR300
VAR302 TO VAR304 VAR306 TO VAR308 VAR310 TO VAR312 VAR314 TO VAR316
VAR318 TO VAR320 VAR322 TO VAR324 VAR326 TO VAR328 VAR330 TO VAR332
VAR334 TO VAR336 VAR338 TO VAR340 VAR342 TO VAR344 VAR346 TO VAR348
VAR350 TO VAR352 VAR354 TO VAR356 VAR358 TO VAR360 VAR362 TO VAR364
VAR366 TO VAR368 VAR370 TO VAR372 VAR374 TO VAR376 VAR378 TO VAR380
VAR382 TO VAR384 VAR386 TO VAR388 VAR390 TO VAR392 VAR394 TO VAR396
VAR398 TO VAR400 (-99,99).
EXECUTE .
Saving Data Locally
Occasions arise when it would be desirable to use Surveyor apart from an immediate connection to the Internet: for example, when using a laptop or tablet computer as an interviewing tool. However, that would require that data be saved directly to the computer's hard drive rather than being archived at Indiana University, and applets like Surveyor ordinarily are not allowed to write files on the computers running them.
The restriction can be circumvented on a specific computer as follows.
- Create a directory to contain Surveyor, and another directory to receive the data. Surveyor expects the first directory to be C:\Surveyor, and the second to be C:\Surveyor\Data. Setting up other directories would require changing code inside of Surveyor.
- Heise will provide a file named surveyor_all.jar containing the applet, the localized Messages file, and all Words files. The file should be put into the C:\Surveyor directory.
- The applet web page (TheWebPage.html) also should be put in the C:\Surveyor directory. The applet web page is the same as discussed above except for the ARCHIVE line which now should read ARCHIVE="surveyor_all.jar", and the InternetSave parameter which now should be set as follows: <PARAM NAME=InternetSave VALUE=false>.
- The Java permissions file, C:\Program Files\Java\jre6\lib\security\java.policy,
must be changed by appending the following line at its bottom (note
that all slashes are forward rather than backward in this line):
permission java.io.FilePermission "C:/Surveyor/Data/-", "write";
With these changes, the Surveyor applet can be run by using one's Internet browser to open file C:\Surveyor\TheWebPage.html. Data from completed sessions will be stored in directory C:\Surveyor\Data. The dat files have exactly the same format as those archived at Indiana University.
![]()
![]()
URL: www.indiana.edu/~socpsy/ACT/SurveyorDocumentation.htm